



When we think about the performance of a database, Indexing is the first thing that comes to mind. Here, we are going to look into how database indexing works on a database. Please note that here, architectural details are described based on SQLite 2.x database architecture. You can find out the backend implementation of SQLite 2.5.0 which is relevant to this blog in https://github.com/madushadhanushka/simple-sqlite along with sample tests.
Btree is a data structure that store data in its node in sorted order. We can represent sample Btree as follows:
 Btree store data such that each node contain keys in ascending order. Each of these key having two references to another two child nodes. Left side child node keys are less than the current key and right side child node keys are more than the current key. If a single node has “n” number of keys then, it can have maximum “n+1” child nodes.
Btree store data such that each node contain keys in ascending order. Each of these key having two references to another two child nodes. Left side child node keys are less than the current key and right side child node keys are more than the current key. If a single node has “n” number of keys then, it can have maximum “n+1” child nodes.
Why indexing used in the database?
Think you need to store a list of numbers in a file and search a given number on that list. The simplest solution is to store data in an array and append values when new value comes. But, If you need to check if a given value exists in the array, then you need to search through all of the array element one by one and check whether the given value is exist. If you are lucky enough, you can find the given value in the first element. In the worst case, the value can be the last element in the array. We can denote this worst case as O(n) in asymptotic notation. this means, If your array size is “n” at most you need to do “n” number of search to find a given value in an array.
How could you reduce this search time? The easiest solution is to sort the array and use binary search to find the value. Whenever you insert a value into the array, it should maintain order. Searching start by selecting a value from the middle of the array. Then compare the selected value with the search value. If selected value greater than the search value, then ignore the left side of the array and search value on the right side and vice versa.
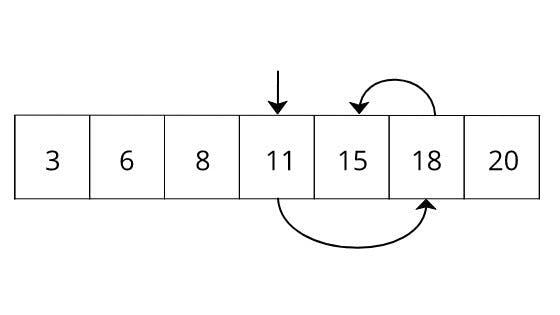
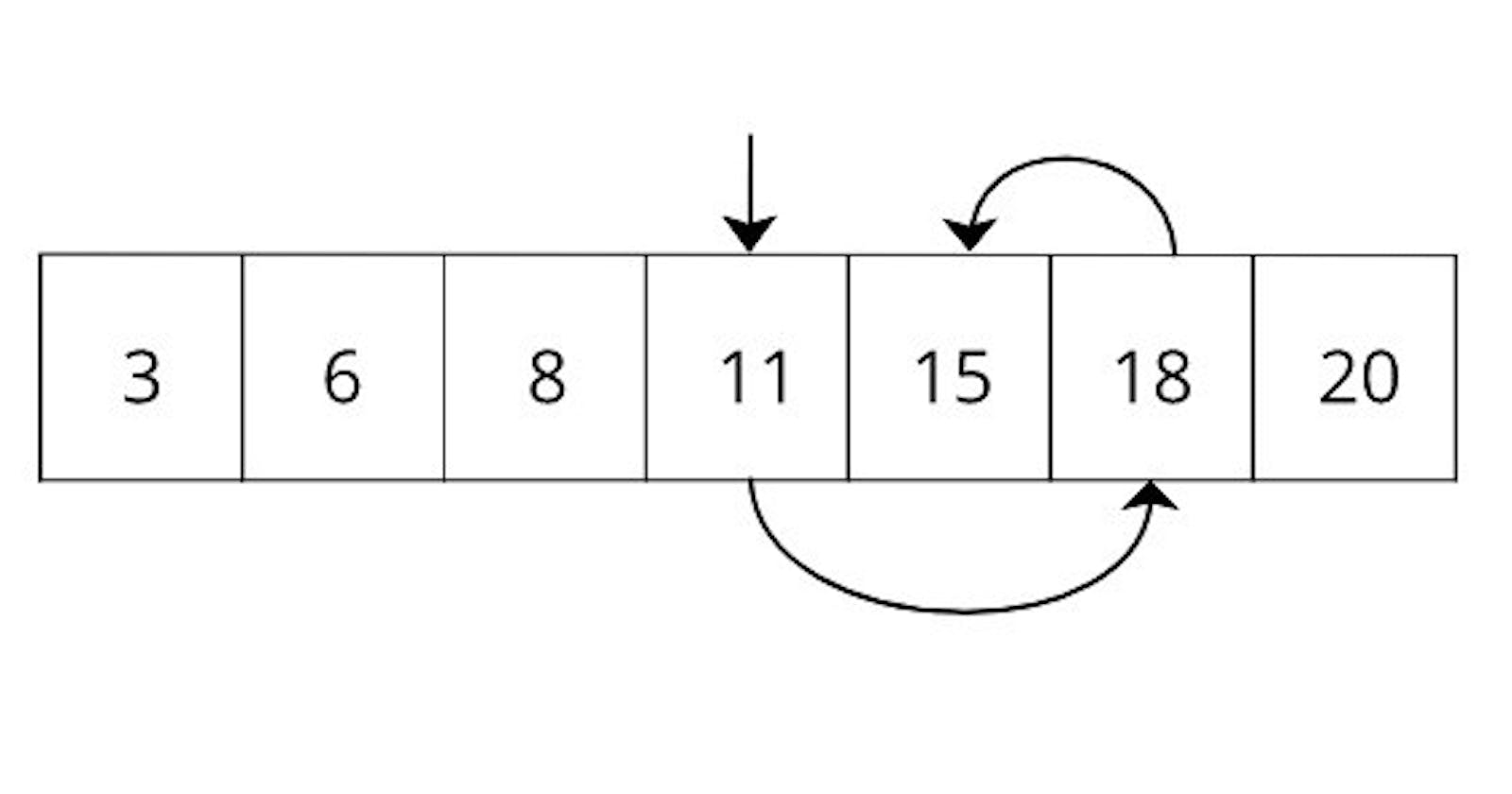
Here, we try to search key 15 from the array 3,6,8,11,15,18 and 18 which is already in sorted order. If you do a normal search then it will take five units of time to search since the element in the fifth position. But, in the binary search, it will take only three searches. If we apply this binary search to all of the elements in the array, then it would be like follows.
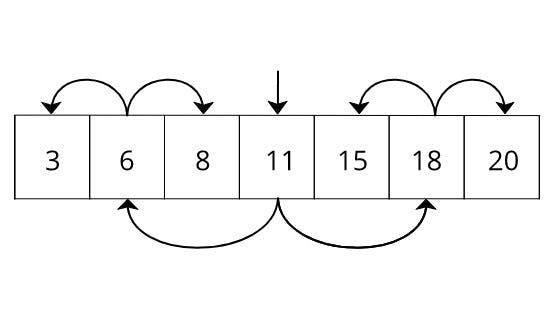
Looking familiar? It is a Binary tree. This is the simplest forms of the Btree. For Binary tree, we can use pointers instead of keep data in a sorted array. Mathematically we can prove worst case search time for a binary tree is O(log(n)). The concept of Binary tree can be extended into more generalized form which known as Btree. Instead of having a single entry for a single node, Btree uses an array of entries for a single node and having reference to child node for each of these entries. Here below some time complexity comparison of each pre-described methods.
┌────────────────┬───────────┬────────────┬───────────┐
│ Type │ Insertion │ Deletion │ Lookup │
├────────────────┼───────────┼────────────┼───────────┤
│ Unsorted Array │ O(1) │ O(n) │ O(n) │
│ Sorted Array │ O(n) │ O(n) │ O(log(n)) │
│ Btree │ O(log(n)) │ O(log(n))) │ O(log(n)) │
└────────────────┴───────────┴────────────┴───────────┘
B+tree is another data structure that used to store data which looks almost same as the Btree. The only difference of B+tree is that it stores data on the leaf nodes. Which means all non-leaf node values are duplicated in leaf nodes again. Here below a sample B+tree.
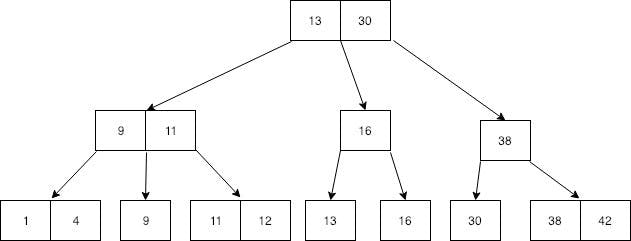 Here 13, 30, 9, 11, 16, 38 non-leaf values are again repeated in leaf nodes. Can you see specialty in this tree at leaf nodes?
Yeah, leaf node includes all values and all of the records are in sorted order. In specialty in B+tree is, you can do the search same as Btree and additionally, you can travel through all the values in leaf node if we put a pointer to each leaf nodes as follows.
Here 13, 30, 9, 11, 16, 38 non-leaf values are again repeated in leaf nodes. Can you see specialty in this tree at leaf nodes?
Yeah, leaf node includes all values and all of the records are in sorted order. In specialty in B+tree is, you can do the search same as Btree and additionally, you can travel through all the values in leaf node if we put a pointer to each leaf nodes as follows.
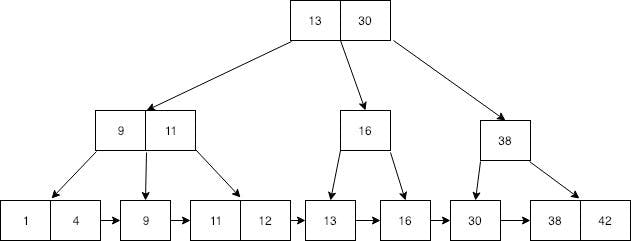
How indexing used in a database?
When Btree comes to the database indexing, this data structure getting little complicated by not just having a key, but also has a value associated with the key. this value is a reference to the actual data record. This key and value together are called a payload. Assume following three column table need to store on a database.
┌───────┬───────┬─────┐
│ Name │ Marks │ Age │
├───────┼───────┼─────┤
│ Jone │ 5 │ 28 │
│ Alex │ 32 │ 45 │
│ Tom │ 37 │ 23 │
│ Ron │ 87 │ 13 │
│ Mark │ 20 │ 48 │
│ Bob │ 89 │ 32 │
└───────┴───────┴─────┘
First, the database creates a unique random index(or primary key) for each of the given record and convert relevant rows into a byte stream. Then it stores each of the key and record byte stream on a B+tree. Here, the random index used as the key for indexing. The key and record byte stream altogether know as Payload. Resulting B+tree could be represented as follows.
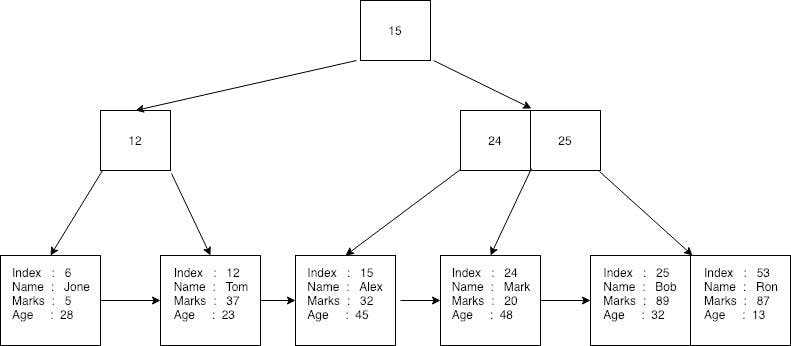 Here you can see, all records are stored in the leaf nodes of the B+tree and index used as the key to creating a B+tree. No records are stored on non-leaf nodes. Each of the leaf nodes has reference to next record in the tree. A database can perform a binary search by using the index or sequential search by searching through every element by only traveling through the leaf nodes.
If no indexing used, Then database read each of these records to find the given record. When indexing enabled, then the database creates three Btrees for each of the columns in the table as follows. Here the key is the Btree key used to indexing. The index is the reference to the actual data record.
Here you can see, all records are stored in the leaf nodes of the B+tree and index used as the key to creating a B+tree. No records are stored on non-leaf nodes. Each of the leaf nodes has reference to next record in the tree. A database can perform a binary search by using the index or sequential search by searching through every element by only traveling through the leaf nodes.
If no indexing used, Then database read each of these records to find the given record. When indexing enabled, then the database creates three Btrees for each of the columns in the table as follows. Here the key is the Btree key used to indexing. The index is the reference to the actual data record.
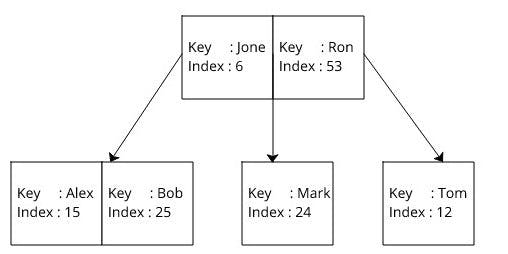
When indexing used First, database search a given key in corresponded Btree and get the index in O(log(n)) time. Then it performs another search in B+tree by using already found index in O(log(n)) time and get the record.
Database Pages implementation
Each of these nodes in Btree and B+tree are stored inside the Pages. Pages are fixed in size. Pages have unique number starts from one. A page can be a reference to another page by using page number. At the beginning of the page, page meta details such as the rightmost child page number, first free cell offset and first cell offset stored. There can be two types of pages in a database.
- Pages for indexing: These pages store only index and a reference to another page.
- Pages to store records: These pages store the actual data and page should be a leaf page.
Conclusion
Databases should have an efficient way to store, read and modify data. Btree provide an efficient way to insert and read data. In actual Database implementation, Database uses both Btree and B+tree together to store data. Btree used for indexing and B+tree used to store the actual records. B+tree provide sequential search capability in addition to the binary search which gives database more control to search non-index value in a database.